|
Microsoft Excel��Microsoft��ʹ��Windows��Apple Macintosh����ϵ�y(t��ng)����X����(xi��)��һ����ӱ���ܛ����ֱ�^(gu��n)�Ľ��桢��ɫ��Ӌ(j��)�㹦�͈ܺD�����ߣ��ټ��ϳɹ����Ј�(ch��ng)�I(y��ng)�N(xi��o)��ʹExcel�ɞ������еĂ�(g��)��Ӌ(j��)��C(j��)��(sh��)��(j��)̎��ܛ���� ��Excel���ٷ���������(ji��n)�Σ���ͬҪ������Ό�(xi��)�ó���һ�ӣ���Ҫ����һ����Փ��������ֲ��E�г���
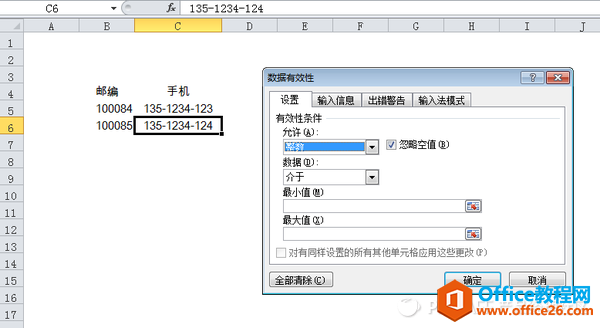
��һ�ӣ�����ݔ���|(zh��)��ͨ�^(gu��)ʹ�á���(sh��)��(j��)��Ч�ԡ����ܣ��p��ݔ����e(cu��)�`���O(sh��)��ݔ�����Ч�ԙz�飨���磺�֙C(j��)̖(h��o)�a��11λ�ȵȣ����M������"Garbage In, Garge Out"��
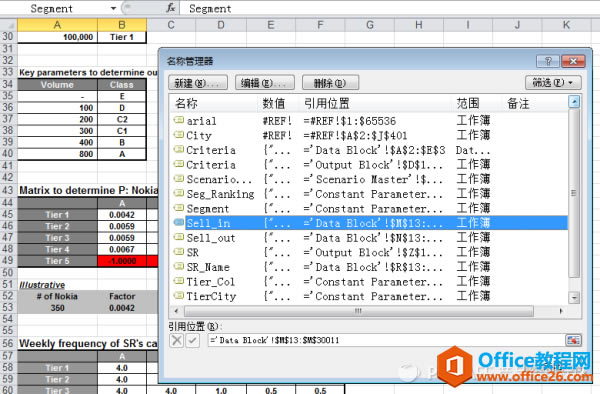
Excel��(sh��)��(j��)ģ���У����ڲ�ͬ�(l��i)�͵Ĕ�(sh��)��(j��)������(sh��)�����{(di��o)����(sh��)�����g�Y(ji��)������K�Y(ji��)���ȵȡ����ٵ��e(cu��)�`�l(f��)���ڻ������N�(l��i)�͵Ĕ�(sh��)��(j��)���߸����˲����{(di��o)�������g�Y(ji��)������Ⱦ��K�Y(ji��)������˿��Կ��]��(du��)��ͬ�Ĕ�(sh��)��(j��)�����ɫ����worksheet�M(j��n)�Ѕ^(q��)�����D���������ɫ��(bi��o)ע��ͬ�Ĕ�(sh��)��(j��)����Щ�ǹ��ĵģ���Щ�����Y(ji��)�������g�^(gu��)�̶������ġ��@Щ��ʩ���Ǟ�����ģ�͵������^(gu��)���Լ��{(di��o)ԇ�^(gu��)���У������`���`�h��(sh��)��(j��)�����Ҫ�������O�£�߀����ʹ���D�ҷ��ķ�����ֱ�����á����o(h��)�����������ܣ���(du��)�����ĵĔ�(sh��)��(j��)�M(j��n)�б��o(h��)��
���⣬��(du��)��һЩ��(j��ng)��ʹ�õ�ݔ��?y��n)^(q��)���磬A1:A299������������(f��)���F(xi��n)��Sum����Vlookup�Ⱥ���(sh��)�У����Կ��]���������x��׃�����������ڡ����Q(ch��ng)�����������M(j��n)���ġ����Ӻ̈́h���ȹ���������(f��)ʹ�õĕr(sh��)��͕�(hu��)�dz����㣬���磺=Vlookup(A1,data,2,false)�@�N��(ji��n)�εČ�(xi��)����
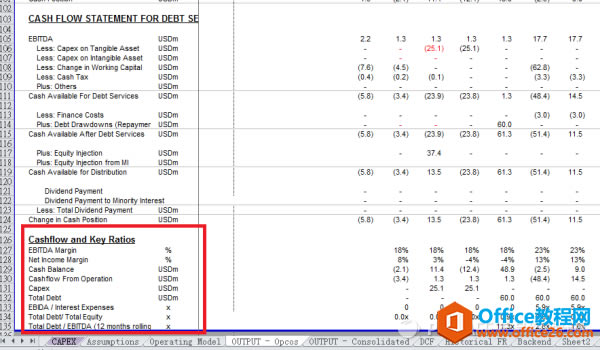
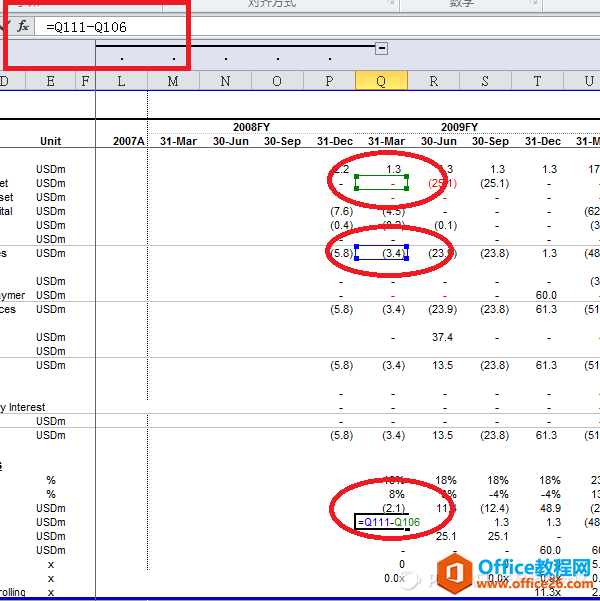
�ڶ��ӣ�����ݔ���|(zh��)��������ݔ���S������������Excelݔ���Y(ji��)���ĕr(sh��)����������Փ�£���ݔ���������^С�ķ��������H�������e(cu��)�`�����ҕ�(hu��)ʧȥ����(g��)ҕ�ǡ�������܉��ڬF(xi��n)��ݔ���Y(ji��)���Ļ��A(ch��)�U(ku��)չ��ҕݔ���ľS�ȣ����ܫ@�ø�ȫϢ��ҕ�ǡ���ؔ(c��i)��(w��)������(b��o)�����ԣ���(d��ng)Ȼ��������ݔ����(j��ng)��Ĉ�(b��o)����ʽ��������܉��Ӌ(j��)��һЩؔ(c��i)��(w��)ָ��(bi��o)�����ں��m��λ�ã����D����ʾ��EBIDTA��Cash flow from operation��EBIDA/Interest Expenses�ȵȣ������H���Բ���У�(y��n)�\(y��n)���^(gu��)�̣�߀�Ķ���(g��)�S�ȷ���(y��ng)��I(y��)��ؔ(c��i)��(w��)��r����(d��ng)ȻҲ�����װl(f��)�F(xi��n)���ܴ��ڵ�Ӌ(j��)���`��Ķ�����ݔ�����|(zh��)����
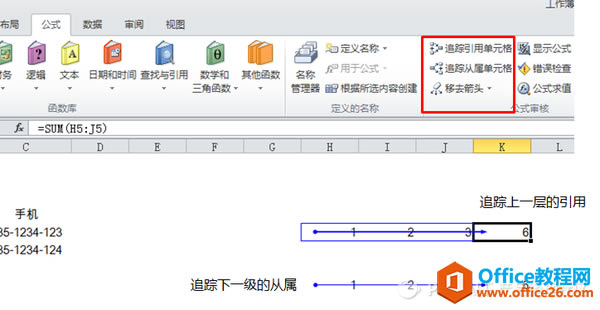
�����ӣ��z�(y��n)�\(y��n)���^(gu��)���(ji��n)�δֱ��ķ�ʽ�����ú���(sh��)���Ќ�(du��)ݔ�벻ͬ�ɫ�Ę�(bi��o)ע����(du��)�\(y��n)���^(gu��)�̼�ݔ��?y��n)��?sh��)�M(j��n)�Йz�飬���Ƿ��_(d��)���A(y��)�ڻ����з����IJ��e(cu��)��
����(j��)һЩ����ͨ�^(gu��)��ۙ����/�Čن�Ԫ����(du��)�\(y��n)���^(gu��)���M(j��n)�Йz�飬�M���ܱ��ʽ�\(y��n)����ݔ��?y��n)��?sh��)�ķ�����
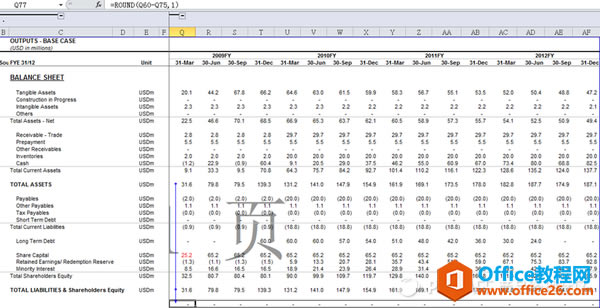
������(j��)һЩ�����Ԍ�(du��)һЩ�P(gu��n)�Iָ��(bi��o)�Լ����ĵ�ʽ���Џ�(f��)�z�����猦(du��)��ؔ(c��i)��(w��)��(b��o)��������A(ch��)�ĵ�ʽ���Y�a(ch��n)=ؓ(f��)��+��(qu��n)�桱������Financial Modeling���^(gu��)���У���Ҫ�O(sh��)�Ì�(zhu��n)�T(m��n)��һ���M(j��n)�Йz�飬�(l��i)���ڻ��W(xu��)����ʽ����ƽ�z�顣
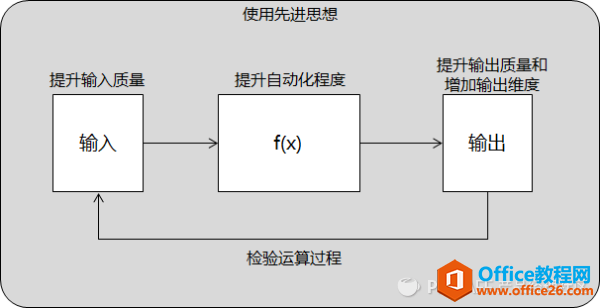
�����v�D�üt�Ę�(bi��o)ע�ĵ��ČӺ͵����
���Čӣ������Ԅ�(d��ng)���̶�������IDE��ʹ�����P(gu��n)�I�~��ʾ�Լ���(j��ng)���z��Code Review��߀�Dz��܌�(xi��)�ó���һ�ӣ��@����߀����·��
�ٱ��磬��������У�Ҫ���ɫ�^(q��)���еľ��Ԫ�ص��������С��м�worksheet�ό�(du��)��(y��ng)��(sh��)�ֵĿ��͡�����k����ÿ��(g��)��Ԫ��(xi��)һ�μӿ�����(sh��)���؏�(f��)��ʮ��ֵ�װٴΣ���(y��ng)ԓ��(hu��)���S����worksheet�����dz����׳��e(cu��)���M(j��n)�A���k�������ý^��(du��)��ַ������(du��)��ַ����(xi��)һ�κ���(sh��)������(g��)��ꇵĺ���(sh��)��ؐճ�N����ɣ����e(cu��)���ʴ�ͣ�����ÿ���F(xi��n)һ��(g��)�µı����Ҫ���º���(sh��)����Ȼ�г��e(cu��)�IJ����ʣ����(j��)���k����������һ��(g��)�k���Ļ��A(ch��)�ϣ�����CELL����(sh��)�@ȡWorksheet�����ֲ��្��(sh��)�֣�Ȼ��һ��dzɣ�����(g��)����ĺ���(sh��)��ȫ�DŽ�(d��ng)�B(t��i)�ģ�Worksheet��(f��)��֮��ֻҪ�ij�����(y��ng)�����־Ϳ�������΄�(w��)���ڳ��e(cu��)����������Ժ�(qi��ng)��
����(sh��)��(xi��)���ǣ�
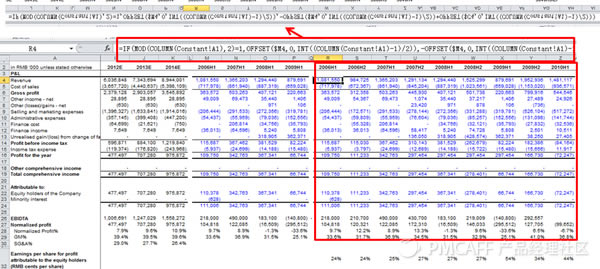
����(sh��)��(xi��)���ǣ�=SUM(('Balance Sheet'!$AA$8:$AA$100='Cash Flow'!$B44)*('Balance Sheet'!O$8:O$100-'Balance Sheet'!N$8:N$100)*('Balance Sheet'!$AB$8:$AB$100))
|
��ܰ��ʾ��ϲ�g��վ��Ԓ(hu��)��Ո(q��ng)�ղ�һ�±�վ��
��վ�l(f��)����Win7������ϵ�y(t��ng)��Win10�������XP������ϵ�y(t��ng)�H�邀(g��)�ˌW(xu��)��(x��)�y(c��)ԇʹ�ã�Ո(q��ng)?ji��n)����d��24С�r(sh��)��(n��i)�h�������������κ��̘I(y��)��;����t�����ؓ(f��)��Ո(q��ng)֧��ُ(g��u)�I(m��i)ܛ����ܛ����
��վ�����YԴȫ����(l��i)���ھW(w��ng)�j(lu��)�YԴ,���ַ������ę�(qu��n)��,Ո(q��ng)���r(sh��)֪ͨ�҂�(peng896066052@126.com),�҂���(hu��)���r(sh��)̎��.
Copyright © 2018-2020 ����ľ�L(f��ng)���dվ